



化學所特聘教授劉如熹研究團隊成果:革命性近紅外螢光材料以結構創新與機制演進開啟應用新篇章 榮登國際頂尖期刊
瀏覽器版本過舊,或未開啟 javascript
請更新瀏覽器或啟用 javascript
更新日期:110年11月25日
利用深度學習剖析人類白血球抗原之各種等位基因辨識抗原的差異
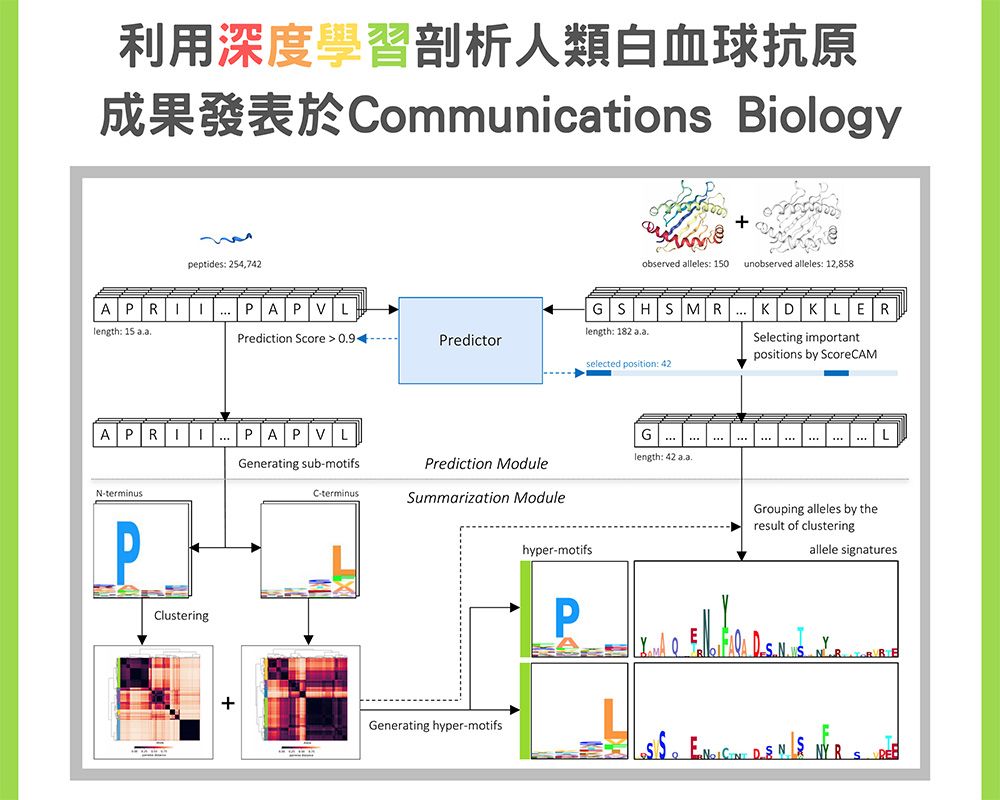
計算與系統生物學研究中心副主任陳倩瑜老師(生物資源暨農學院生物機電工程學系)領導研究團隊與臺灣人工智慧實驗室合作,團隊成員包括中心主任阮雪芬老師(生命科學院生命科學系)與中央研究院資訊科學所蔡懷寬研究員,利用深度神經網路對第一類MHC蛋白質(MHC class I,MHC-I)會結合進而表現的胜肽序列特徵進行學習,研究成果近期發表於Nature出版的期刊Communications Biology,所開發的工具MHCfovea (https://mhcfovea.ailabs.tw/),將人類對各種等位基因的瞭解,從原先有實驗數據的150種,擴充到13,008種,展示深度學習在多體學大數據能扮演的關鍵角色。
MHC-I在人類身體中的功能,是負責辨識特定的胜肽序列片段(peptide),然後一起移動到細胞膜上,讓T細胞知道可能有因為感染所產生的外來抗原,或是因為癌症所產生的新生抗原。舉例來說,新冠病毒入侵人體後,會利用人類的細胞製造病毒蛋白,這些蛋白質的片段就有可能被 MHC-I辨識,進而通知T細胞啟動免疫反應。MHCfovea首先利用150種有實驗數據的等位基因進行深度學習,再用所建立的模型預測其他12,858種等位基因所辨識的序列,並將所得到的序列特徵進行分群整理,歸納出32個等位基因的重要胺基酸與其結合特徵(motif)的配對關係。
MHCfovea共使用395,581筆實驗數據,搭配超過2千萬條的人類蛋白質序列片段來增加負樣本的數量,每一筆資料包含一條長度為182的蛋白質序列和一段長度為8~15的胺基酸片段,用來訓練深度學習模型。為了解決正負樣本比例懸殊的問題,MHCfovea運用降低取樣 (down-sampling) 的技術,先將負樣本切分成多組資料,每一組都搭配相同的正樣本建立預測模型,最後再用整合學習 (ensemble learning) 的概念將預測結果整合。MHCfovea比起現有的其他預測工具提供更精準的預測結果,涵蓋更多的等位基因,預期能有效幫助研究人員在抗原分析與疫苗設計時將不同等位基因特性納入考量,達到精準標的或個人化治療之終極目標。
Communications Biology 研究成果全文:https://www.nature.com/articles/s42003-021-02716-8



